Project : Systematic reviews (SRs) - the librarian-assisted literature survey of scholarly articles takes time and requires significant human resources. Given the ever-increasing volume of published studies, applying existing computing and informatics technology can decrease this time and resource burden. Due to the revolutionary advances in (1) Generative AI such as ChatGPT, and (2) External knowledge-augmented information extraction efforts such as Retrieval-Augmented Generation, In this work, we explore the use of techniques from (1) and (2) for SR. We demonstrate a system that takes user queries, performs query expansion to obtain enriched context (includes additional terms and definitions by querying language models and knowledge graphs), and uses this context to search for articles on scholarly databases to retrieve articles. We perform qualitative evaluations of our system through comparison against sentinel (ground truth) articles provided by an in-house librarian.
Project : The AIISC Knowledge Graph (KG) EMPWR effort involves the development of a comprehensive tool and platform for KG development with the following aims a) Develop a KG development platform capable of instantiating KGs in any domains from structured, semi-structured, and unstructured data: Biomedical & pharmaceutical domain with Percuro b) Improve & address the limitations of existing KG platforms c) Constructs a Knowledge Graph (based on a combination of)
Project : In this demonstration, we introduce the first PDDL formulation for the 3-dimension RC and solve it with an off-the-shelf Fast-Downward planner. We also create a plan executor and visualizer to show how the plan achieves the intended goal.
Project : We introduce Plansformer; an LLM fine-tuned on planning problems and capable of generating plans with favorable behavior in terms of correctness and length with reduced knowledge-engineering efforts.

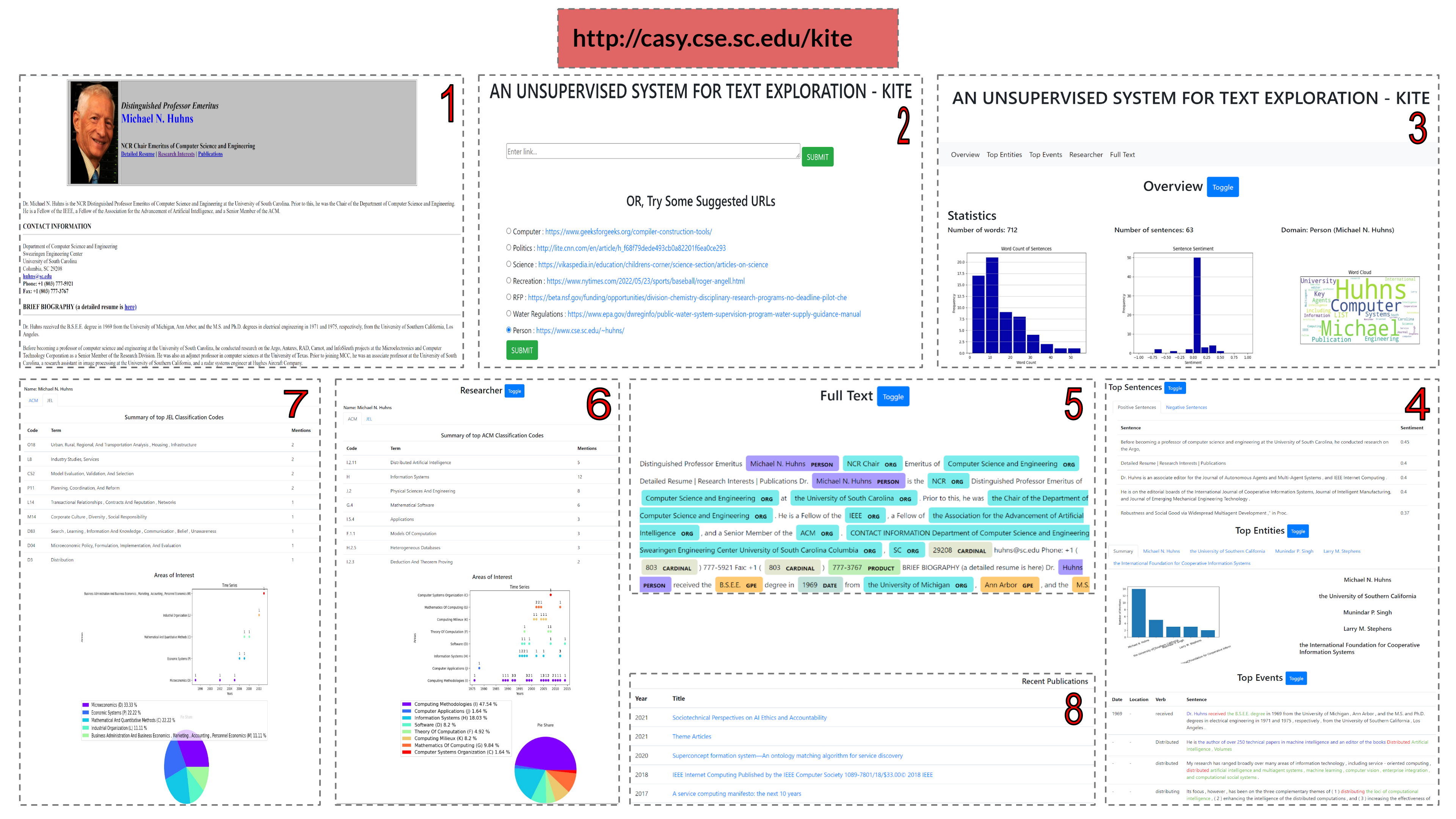
Project : We present an unsupervised system, called KITE, for exploring textual data which can generate insights from a general as well as domaindependent perspective consisting of holistic views, entity-centric view, events view, domain-specific interpretation using industry taxonomies and a detailed full-text view transparently connecting the document to insight elements.
Project : We demonstrate ALLURE, an educational AI system for learning to solve the Rubik’s cube that is designed to help students improve their problem solving skills.
Project : We present a generic approach for dialogs for information retrieval based on automated planning within a reinforcement learning (RL)-based platform, ParlAI.
Project : We introduce ULTRA, a novel AI-based system for assisting team formation when researchers respond to calls for proposals from funding agencies.
Project : SPOKES: Community-Driven Data Engineering for Substance Abuse Prevention in the Rural Midwest
Keywords : #NSF, #COVID19, #Social_Impact, #Psychological_Impact, #Addiction, #Mental_Health, #Social_Quality_Index
Project : Convergence Accelerator: Actionable Sensemaking Tools for Curating and Authenticating Information in the Presence of Misinformation during Crises
Keywords : #NSF, #DisasterManagement #Hurricane #SocialMedia #Misinformation
Project : Hazards SEES: Social and Physical Sensing Enabled Decision Support for Disaster Management and Response
Keywords : #NSF, #DisasterRecord, #Real_time_SocialMediaAnalysis, #Coordination #Multimedia #SatelligeData
Learn more about this project here...
kBot is a knowledge-driven personalized chatbot system designed to continuously track pediatric asthmatic patient to monitor relevant health and environmental data including medication adherence. The outcome is to help asthma patients self manage their asthma progression by generating trigger alerts and educate them with various self-management strategies.
ABC-AI is an interdisciplinary project between the Artificial Intelligence Institute at the University of South Carolina (AIISC@UofSC) and the Aging Brain Cohort at University of South Carolina (ABC@UofSC) developed to identify cognitive decline/impairment among healthy older adults.
Alleviate is the demonstration of the alleviate mental health chatbot which acts as a virtual counselor for patience and assist care providers.
Obvio is a graph-based framework for exploring biomedical literature. It automatically generates subgraphs on multiple thematic dimensions that capture the multifa.
Keywords : Literature-based discovery (LBD), Graph mining, Path clustering, Hierarchical agglomerative clustering, Semantic relatedness, Medical Subject Headings (MeSH), MEDLINE
BMW Greenville/Fraunhofer material planners custom dashboard.
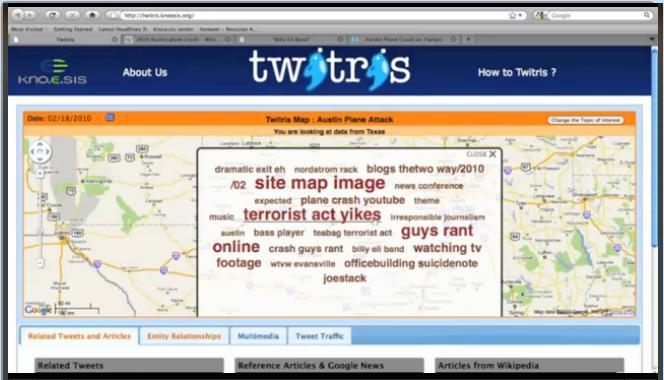
Twitris is a Semantic Social Web application for extraction social signals and understanding social perceptions by Semantics-based processing of massive amounts of event-centric social data. Twitris 2.0 addresses challenges in large scale processing of social data, enabling us to understand events along spatio-temporal-thematic-sentiment dimensions. Twitris 2.0 also covers context based semantic integration of multiple Web resources and expose semantically enriched social data to the public domain. More recently, Twitris is adding People-Content-Network analysis, real-time support (using Twarql), and continuous semantics.
Keywords : Twitter analysis, Social data analysis, Social signal extraction, Social perception, Spatio-temporal-thematic-sentiment processing of social data, People-content-network analysis of social data, Event analysis on social media, Real-time analysis of social media, Social media continuous semantics.

BLOOMS is an ontology alignment system based on the idea of bootstrapping information already present on the LOD cloud. It was developed particularly for Linked Open Data schema alignment. BLOOMS is an acronym for Bootstrapping-based Linked Open Data Ontology Matching System.
Keywords : Ontology Alignment, Schema Matching, Semantic Web, Bootstrapping, Linked Open Data Schema Alignment.

SemSOS is an extension of SOS to allow SOS queries and access to an ontological knowledgebase. Main contributions include: (1) sensor/observation ontology based on Observations and Measurements (O&M;), (2) semantic annotation of O&M; and SML documents, (2) mappings and translation scripts to convert O&M; and SML into RDF (and vice-versa), (3) rule-based reasoning to infer events from low-level sensor data, (4) query translation from SOS format into SPARQL.
Keywords : sensor, Semantic Web, Sensor Web Enablement, sensing-as-a-service.
This demo helps in visualizing the perception cycle (abductive inference) and reputation values computed for weather stations over a period of six days. Various features inferred from raw sensor data using the perception cycle are depicted with different colors of the bars and height of the bar represents the reputation value of each weather station. The demo shows all the inferred features and the way in which the reputation computation converges. Main contributions include: (1) Development and formalization of perception cycle (2) Implementation of a reputation system which used beta-pdf distribution to compute trust values.
Keywords : Trust on sensor networks, Trusted Perception, Sensor Networks.

Real Time Feature Streams focuses on reasoning over lower-level raw sensor data streams to detect higher-level abstractions called features (a concept that represents a real world entity like Blizzard, RainStorm etc) in real-time. The feature-streams are added to the Linked Open Data Cloud (LOD).Main contributions involve: (1) Integration of multiple, multimodal, heterogeneous low-level sensor data streams to generate high-level feature streams. (2) The summarization is across the thematic dimension involving multiple data streams and the use of background knowledge as opposed to summarizations of single streams across temporal dimension (like min,max,average etc).
Keywords : Sensor Streams, Feature Streams, Sensor data annotation.
Scooner users largely automatically generated background knowledge to support deeper insights and knowledge discovery from text. Knowledge base is used for semantic extraction. A semantic search and browsing is supported as iterative process involving ontology-guided exploration or trail-blazing that focuses on relationships, and not just entities. Current version shows how biologists in Human Performance and Cognition (HPCO) research can find insights from the corpus of all of 18+MM PubMed abstracts far better than using a PubMed search.
Keywords : semantic browsing, triple extraction, domain model creation, relationship web, pattern-based extraction, information extraction, ontology-guided exploration, trail blazing, semantic search.

S3space is a social lab for querying linked data. It can also be referred to as a 'SPARQL repository'. It's a platform for SPARQL users to test and verify their SPARQL queries. Users can learn how to query linked data as well as share and save the queries they have built. With syntax highlighting code editor, writing SPARQL is even easier.
Keywords :
Kino (Also known as KinoE ) is a Web document annotation and indexing system that helps scientists annotate and index Web documents. Kino uses a browser plugin to add annotations and a Apache SOLR based backend to index and store the Web pages.
Keywords : SA-REST, APIHut, Scientific document annotation,Semantic annotation of biomedical documents, Semantic service annotation, Kino

Doozer is an application that aims at generating or extracting a domain model from Wikipedia or other similarly structured knowledge sources. It takes as input an incomplete description of a domain, such as a query or list of seed concepts. Doozer then expands on these seeds to get related concepts, which are then again evaluated regarding their indicativeness of the domain. The output is an extended model that still focuses on the intended domain.
Keywords : Doozer, Knowledge extraction, domain model
iExplore is a web tool with a graphical interface for interactive knowledge exploration, that allows non-technical users to explore the integrated knowledge bases. iExplore is designed for domain experts who do not necessarily need to know schema or how to write SPARQL. It is easy to use with just a click of the mouse.
Keywords : iExplore, Semantic exploration, data integrated, UMLS, Chagas Disease
OntoANT is a web tool that allows non-technical users to annotate the data into RDF. The tool let the domain experts to define the triple in the schema level, and then it automatically generates web forms responding to the schema pattern. It also captures the provenance of each triple generated in the knowledge base.
Keywords : OntoANT, Annotation, Provenance
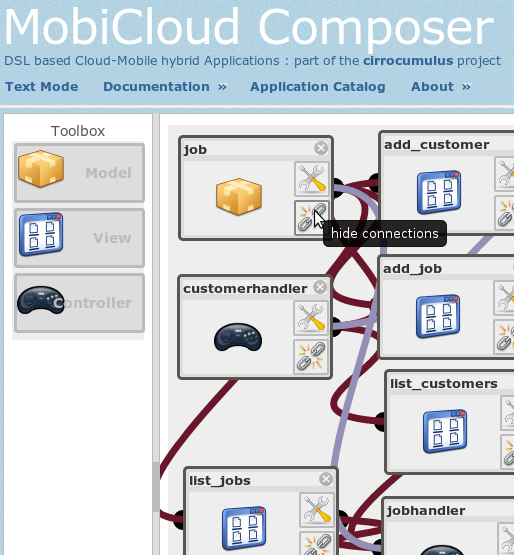
MobiCloud is a Domain Specific Language (DSL) based platform agnostic application development paradigm for cloud-mobile hybrid applications. A cloud-mobile hybrid is simply an application that partially runs on the mobile device and in the cloud. MobiCloud makes it extremely easy to develop these applications and deploy them to clouds and mobile devices.
Keywords : Cloud computing, program generation
Awards : Technology award at the Fukuoka Ruby innovators
This demo is a Semantic Web research effort towards a Physical-Cyber-Social system that uses background knowledge on the web, and an ontology of perception, to reason over the sensor observations generated by a mobile robot.
Keywords : Perception Ontology, Physical-Cyber-Social System, Robot with Background Knowledge
Awards : Technology award at the Fukuoka Ruby innovators
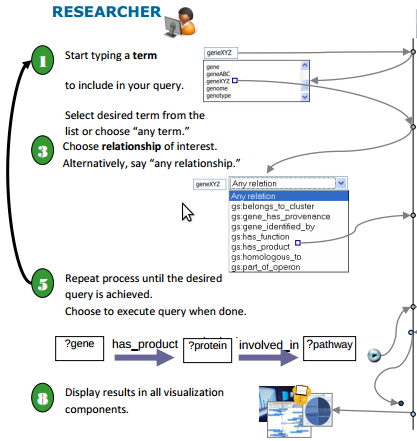
Cuebee is a flexible, extensible application for querying the semantic web. It provides a friendly interface to guide users through the process of formulating complex queries. No technical knowledge of query languages or the semantic web is required. They key enabler of the query builder is the ontology schema. The schema provides the types and possible interconnections of data to guide the user in creating a query.

Knowledge-Aware Search is a hybrid approach to domain specific information retrieval that goes beyond ontology-driven query interpretation as well as beyond synonym-based query expansion used in Information Retrieval (IR). A knowledge-aware search platform is more amenable to domain specific searches involving complex information needs than general-purpose search frameworks.
Keywords : Semantic Search, Domain Specific Information Retrieval, Complex Information Needs, Ontology, Background Knowledge, Context-Free Grammar